

What is the difference between Orthogonal Descent and Damped Least Squares?

Solved
OD vs. DLS
Best answer by Sarah.Grabowski
There are two local optimization algorithms: Orthogonal Descent (OD) and Damped Least Squares (DLS).
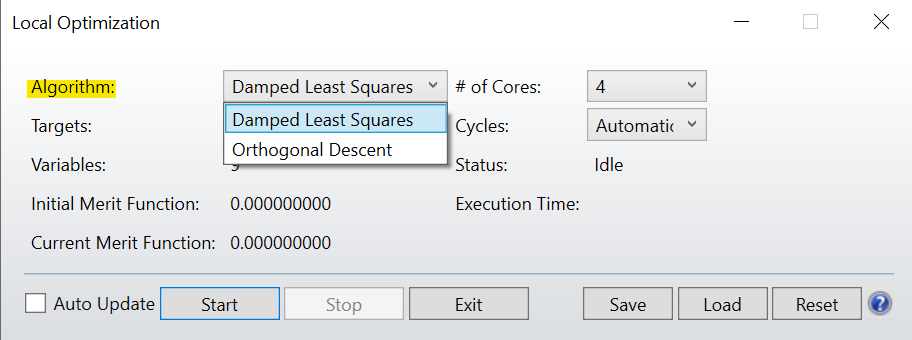
The OD algorithm uses an orthonormalization of the variables, then samples the solution space discretely in an attempt to decrease the merit function. DLS, on the other hand, actually calculates the numerical derivatives to determine what direction of change will result in a lower merit function. DLS is generally recommended, but for systems where the solution space is quite noisy, like illumination design or other non-sequential systems, the OD algorithm will likely outperform the DLS optimizer.
This applies anywhere these algorithms are used such as in Hammer optimization, Global optimization and tolerancing.
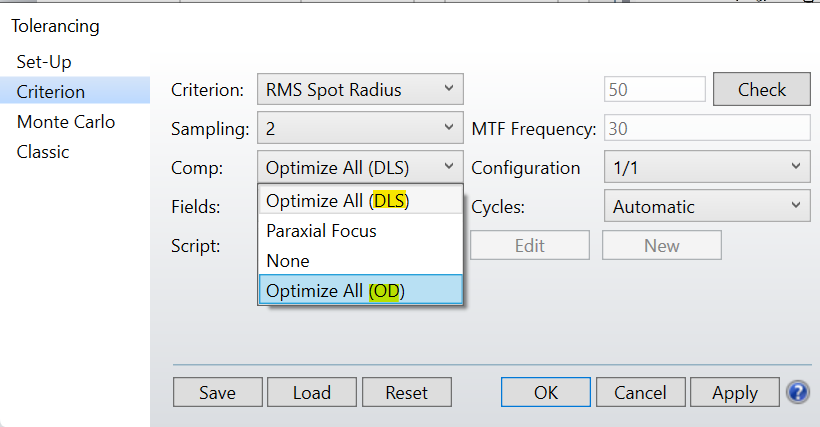
For example, to optimize the compensators in your system (and not just the paraxial back focus), you choose between “Optimize All (OD)” or “Optimize All (DLS)”. The first will just use the OD algorithm, while the second will use an initial cycle of OD followed by the DLS algorithm. OD is good for rough adjustments, and though I just said it is usually used for non-sequential systems, it is also useful in this application in tolerancing sequential systems.


Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
Need more help?
To Chinese users:
Do not provide any information or data that is restricted by applicable law, including by the People’s Republic of China’s Cybersecurity and Data Security Laws ( e.g., Important Data, National Core Data, etc.).
不要提供任何受适用法律,包括中华人民共和国的网络安全和数据安全法限制的信息或数据(如重要数据、国家核心数据等)。