I am mostly running Zemax OS on my laptop, based on Intel i7 4 x 2.9Ghz 16GB RAM (Win 10 Enterprise, 64-Bit), to speed up simulations, I recently started using workstation with AMD Ryzen Threadripper 3970X 32-core 3.7Ghz 128GB RAM (Win 10 Enterprise, 64-Bit). Pure NSC raytracing is about 8 times faster on the workstation then on my laptop. However, on the same NSC optimization tasks I am getting longer optimization times on the workstation.
For example, comparing with the results from the KA-01591 How to optimize non-sequential optical systems
Intel Quad Core CPU (2.90 GHz) and 16GB of RAM (as stated in KB Article)
Algorithm MF Value On-axis brightness (Cd) Time for optimization
DLS 6.69 238 4.4 min
OD 6.68 254 6.5 min
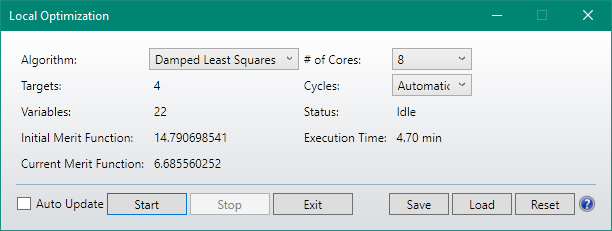
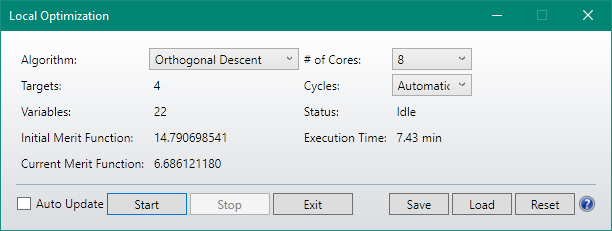
My laptop i7 4 x 2.9Ghz 16GB RAM
Algorithm MF Value On-axis brightness (Cd) Time for optimization
DLS 6.686 238 4.70 min
OD 6.686 248 7.43 min
AMD Threadripper 3970X 32-core 3.7Ghz 128GB RAM
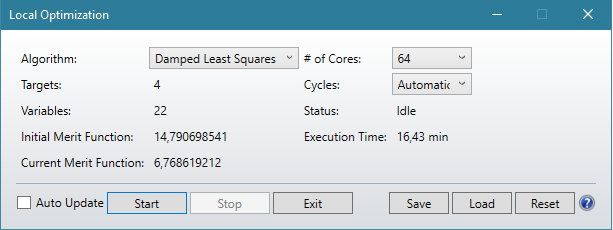
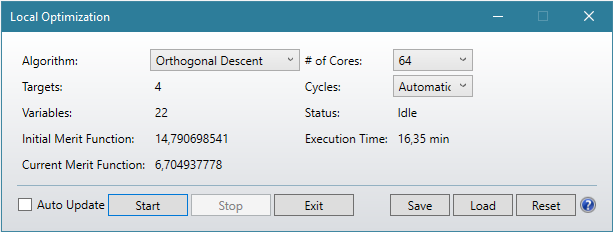
Algorithm MF Value On-axis brightness (Cd) Time for optimization
DLS 6.77 217 16.43 min (not finished)
OD 6.70 253 16.35 min (not finished)
Screenshots
My laptop i7 4 x 2.9Ghz 16GB RAM
DLS OD
DLS OD
AMD Threadripper 3970X 32-core 3.7Ghz 128GB RAM
DLS OD
DLS OD
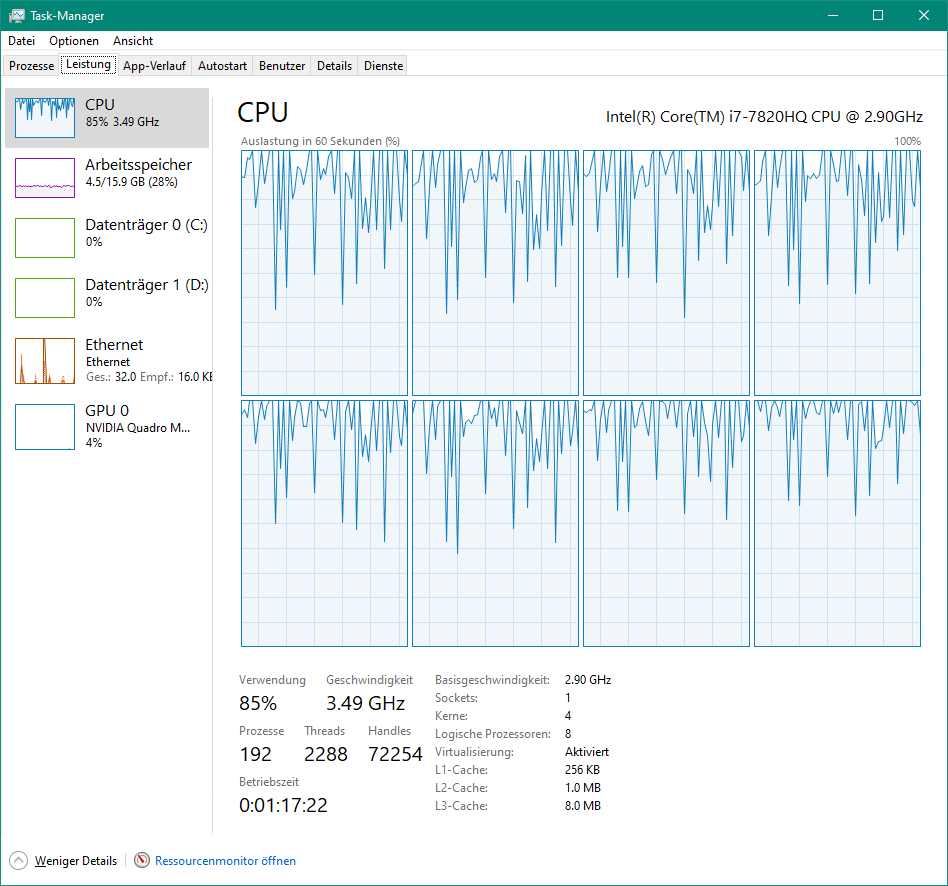
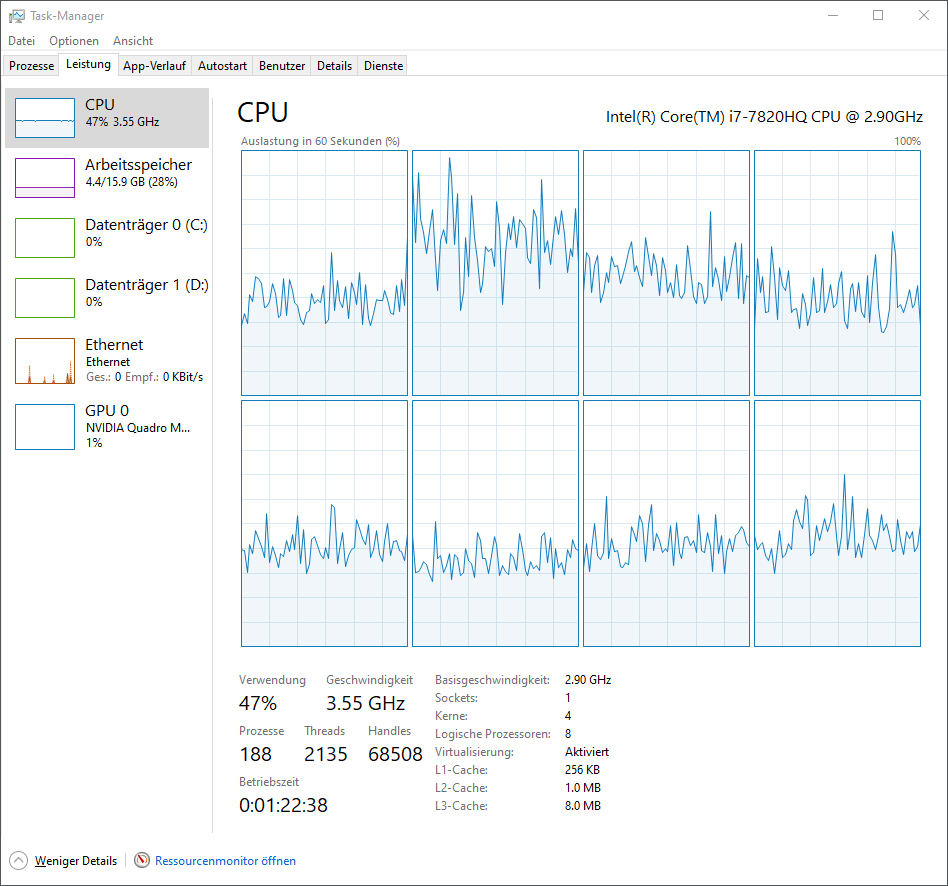
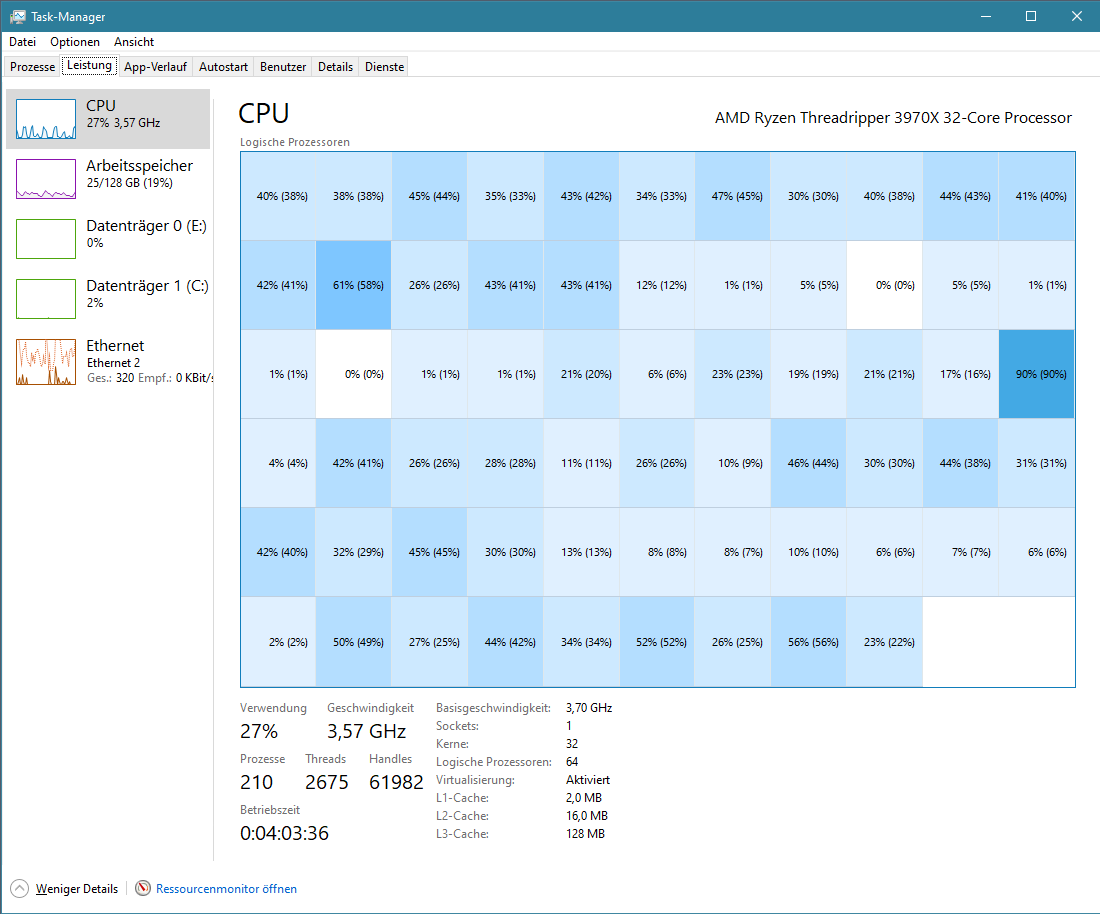
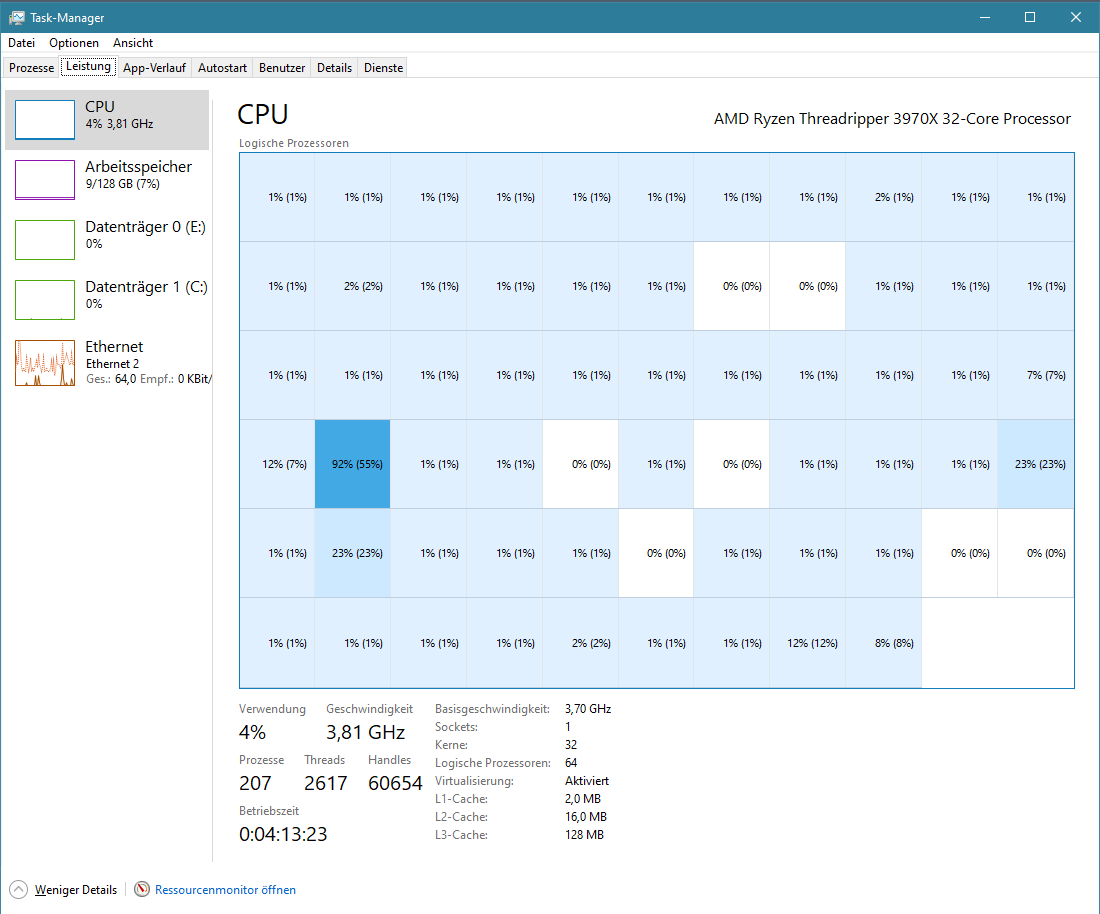
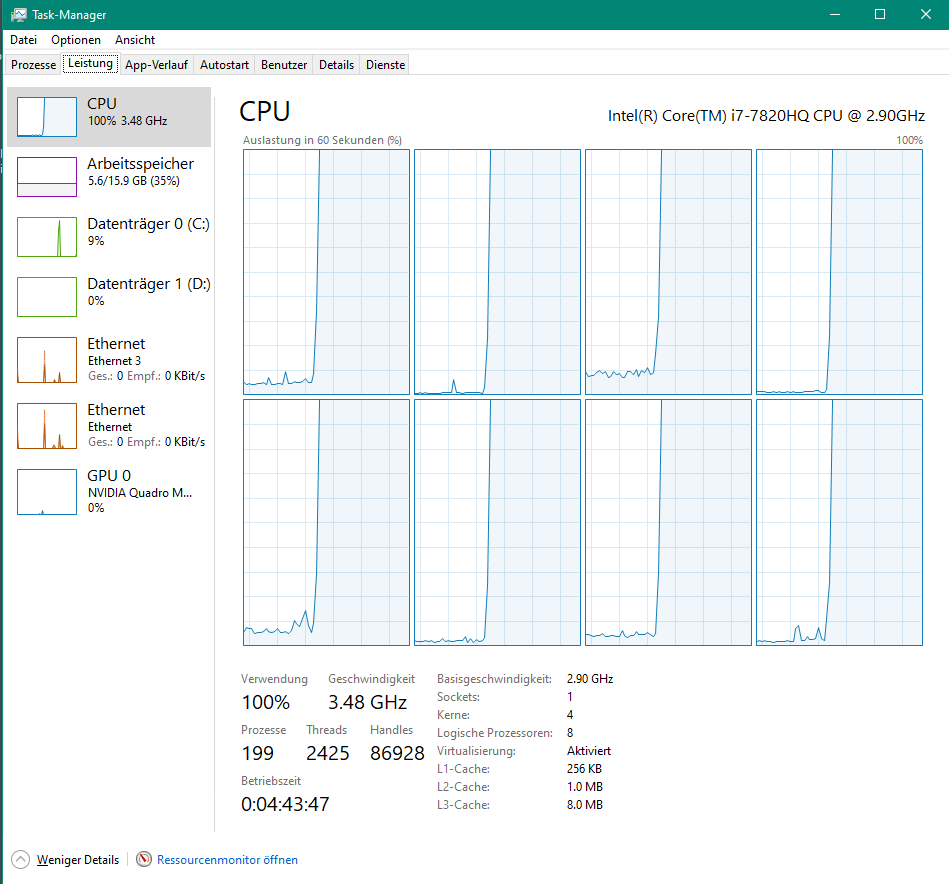
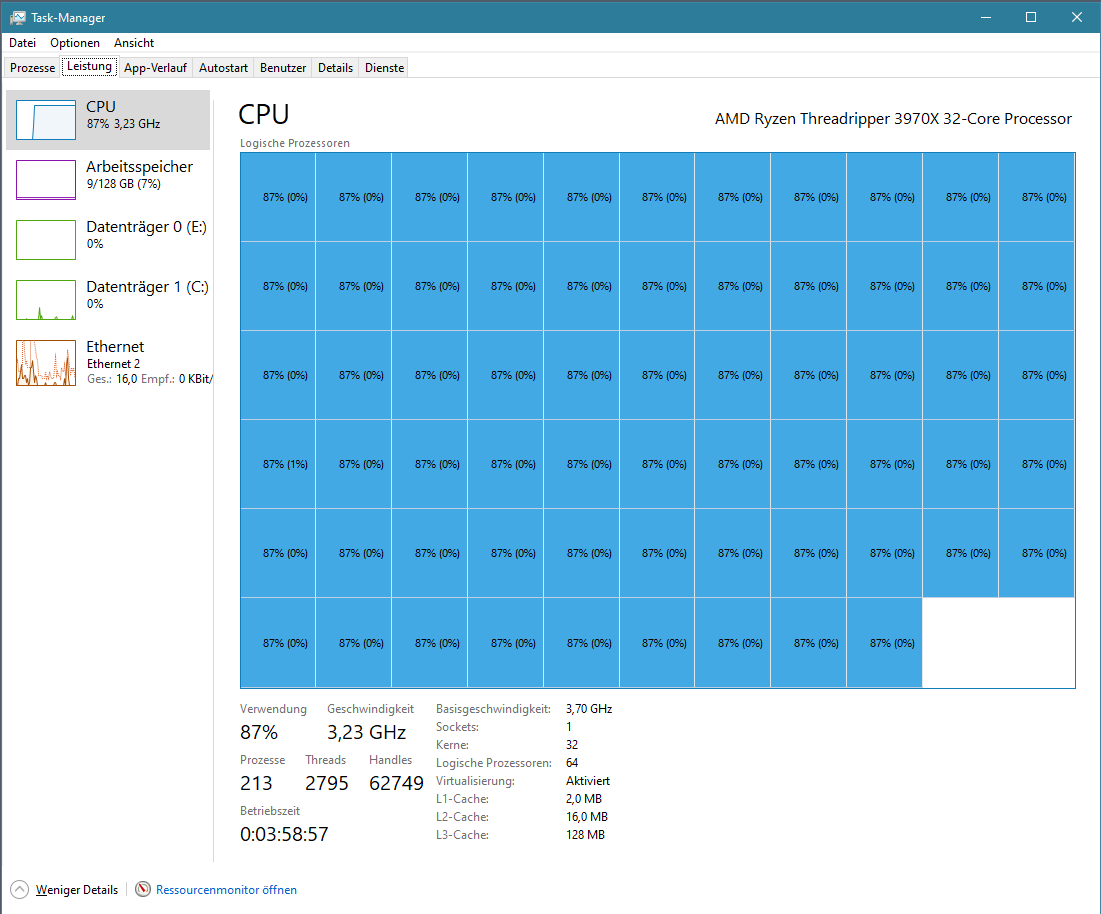
From the task manager it can be seen that the processor usage is very low during optimization on the workstation, not sure why. During pure NSC raytracing it looks better
NSC Raytracing
My laptop i7 4 x 2.9Ghz 16GB RAM AMD Threadripper 3970X 32-core 3.7Ghz 128GB RAM
But is still higher processor usage on my laptop than on workstation 100% vs. 87%
The KA-01591 article also shows universal plot with central pixel intensity vs. curvature of the mirror. Just refreshing this plot alone takes 1.7 min on the workstation and 20 sec on my laptop.
I am currently running Zemax OS 21.1.2 on the workstation and Zemax OS 20.3 on my laptop. Has someone experienced similar problems and/or knows what could be the cause for this sluggish performance on a much better HW setup ?
Best answer by Mark.Nicholson
Hi Peeps,
This question of ‘using more cores efficiently’ is the mirror image of the other frequently asked question, ‘why does OS not use all cores’.
OpticStudio allows the user to select the number of cores used:
We default this to the actual number of cores present but allow the user to change this. The actual number of cores is a good default to use, but there are many reasons why you might want to choose a (usually smaller) number, and some cases where you would want more cores than are actually present.
The reference to Amdahl’s Law is excellent...no calculation can be parallelized 100%, and there is always some upper limit on the gains to be had with parallelization. But there’s more to it than that. When we launch a new thread containing a parcel of rays to be traced, we also have to make a copy of the entire lens system for those rays to interact with. Making a copy of the lens data adds overhead, as does receiving the finished thread back and copying its data out, asking the operating system if it has room for more threads, and so on.
In non-sequential ray tracing it can be very difficult to estimate how many rays to trace per thread because the number of rays is not conserved. If ray-splitting or scattering is present, we may generate many more rays than the initial launch amount. So, while OS does use some good intelligent strategies to optimize the thread number, there is still room for the user to have some control as well.
BTW, in the context of specifying the number of cores when buying a new machine, more is always better (you can choose to use less if desired) but the amount of memory per core, and the type of memory per core is also very important. Each thread gets a full copy of the lens data, which may include CAD objects, Boolean objects, fluorescence and other scattering data and so on. That’s a lot of memory to move around (look at System...Check to see how much memory is needed per thread). It’s important that each thread can have that amount of cache memory per core so it doesn’t have to read and write to disk (even SSD) for this.
I have replied to you directly by email last week since our forum was being transferred to the new platform but I thought it could be useful to keep the discussion here for other users.
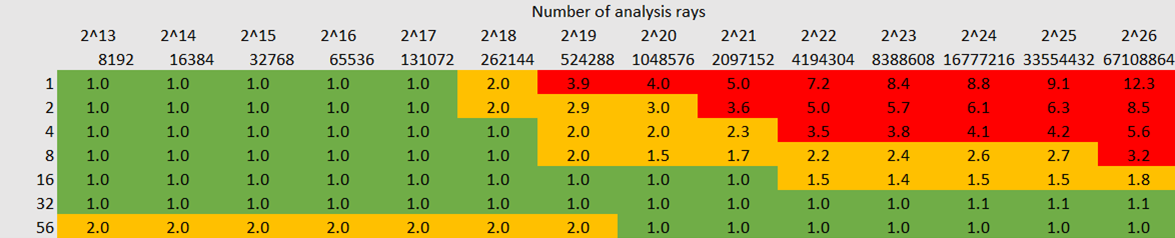
We have noticed that there is a sort of a linear relationship between the number of cores and the number of analysis rays used when optimizing. Too many cores gives a penalty when the number of analysis rays is not high enough.
Below is a result from a user using a AMD Ryzen Threadripper 3970X 32 Core Processor, 3693 Mhz (32 Core(s), 64 Logical Processor(s)).
As you can see, a high number of cores is helpful for a high number of analysis rays but leads to a penalty time for a low number of rays.
We ran similar tests internally here on an Intel-Xeon-Platinum-8180 28 cores (56 threads) and got similar results (I need to re-run the last line):
So far we have run tests and collected results. So we are aware of the problem but it is just started to be investigated.
For the ray tracing, we didn’t observe a penalty except for a low number of rays.
But one of my IT colleague wrote a little description about parallel computing and I think this provides an insight on the situation.
There is a famous theory in parallel computing called Amdahl’s law. By understanding this, it will help you understand how cores affect the speed. Here is the wiki for reference https://en.wikipedia.org/wiki/Amdahl%27s_law.
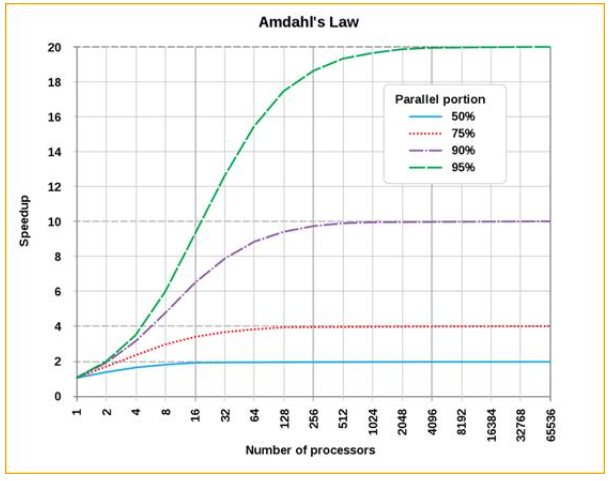
The following screenshot comes from the wiki page.
x-axis represents the number of cores and y-axis represents the speedup.
Each line with different colors represents the amount of parallel portion in the program
For example, ray-tracing can easily use parallel computer since each ray is independent. In this case, the amount of parallel portion can be high.
But when computing a merit function (and therefore optimizing), the software needs to wait the result from previous calculations. In this case, the amount of parallel portion can be low.
With that being said, if 95% of the calculation could be parallelized, we can see on the graph that above 256 cores, the speedup slows down. And this is an ideal case.
So back to OpticStudio, we can expect to have parallel portions between 50% and 75%. In that case (and according to our own testing), 8 or 12 cores seems like a good choice.
I hope that provides a bit of context, but as I said, we are still in the early stage of this investigation, so let us know if you have any other feedback. Have a nice day!
Here is my last reply emailed to you also posted here.
I did not use any of the options in Zemax, Turn Off Threading or # of Cores, these where leaved at their defaults.
I have used AMD Ryzen Master (official AMD software utility for CPU settings) to directly change the number
of cores and turn on/off multi-threading (called SMT by AMD, think this is the same as Hyper-Threading in Intel),
this changes required to restart my system. I managed to overlook that there is an option to set the number of cores directly in the Zemax dialog boxes.
The Ryzen Master allows to set the number of active cores while SMT (multi-threading) is turned on or off.
SMT on/off toggles doubling of the number of logical processors the operating system sees.
Example
32 physical cores selected and SMT on
-> Operating system sees 32 cores (physical) and 64 logical processors (2 threads per core)
32 physical cores selected and SMT off
-> Operating system sees 32 cores (physical) and 32 logical processors (1 thread per core)
The same thing is with other number of cores. For example, if I set 32 cores with SMT off or 2 cores with SMT off I will have
32 cores (physical) vs. 2 cores (physical), this will clearly influence optimization/raytracing speed results.
Thank you for pointing out that the number of cores can be changed in Zemax directly and providing the guideline tables.
This is definitely not my area of expertise, but have you compared the graphics cards? Also, is your processor fan/cooling system working properly in the workstation? Maybe it’s set to a quiet mode? Also, Windows has power plan settings that impact processor power management. That’s under “Change advanced power settings”, under Control Panel/Hardware and Sound/Power Options/Edit Plan Settings, at least on my machine. Where it says Processor Power Management, the minimum and maximum processor states should be set to 100%. Maybe yours is set to 87%?
I am the user who’s results were quoted by Sandrine. I investigated this problem quite deeply. What I learned…
Playing with processor control programs has absolutely no effect.
Large number of cores are in general detrimental to a fast solution - 8 seems to be nice compromise.
In order to find out how many cores to use in NS, a simple test is look at a simple ray trace and see how many cores this is the fastest at. A simple macro can test this. Then use that number of cores in the optimization routines.
The frustration is that if more rays are used more cores becomes more efficient, however the time per optimization cycle still goes up.
The best computer is therefore the one with the highest single core speed and a reasonable number of cores say 8-12.
More cores do help for global optimization.
I do understand that this is a deep problem for Zemax to solve because it is at the core of their algorithms, however it is an increasingly competitive environment and I am glad that other people find the same problem so it can raise its importance for Zemax.
If anyone is interested I can share my report I made on the topic as well as the macros I used to test the speed with a varying number of cores.
Yes, it would be great if OpticStudio could use more cores efficiently.
I researched quite a bit before choosing a processor in 2017. You can find a discussion on LinkedIn about it in the Zemax user’s group. Some people were advocating for maximum core/thread count, but there’s a trade between speed and # cores. I chose the new Intel i9-7900x, based on its high single thread speed (usually runs at about 4.3 GHz when raytracing and can get up to 4.5 GHz in turbo mode) and reasonable number of cores . Only 10 cores and 20 threads, but they all run at 100%. I’ve been happy with it. I’m surprised though, that 5 years later I can’t at least triple my optimization speed by upgrading my processor. Is that what I’m hearing? I wonder what speeds others are getting. Any benchmarks posted for high speed machines?
This question of ‘using more cores efficiently’ is the mirror image of the other frequently asked question, ‘why does OS not use all cores’.
OpticStudio allows the user to select the number of cores used:
We default this to the actual number of cores present but allow the user to change this. The actual number of cores is a good default to use, but there are many reasons why you might want to choose a (usually smaller) number, and some cases where you would want more cores than are actually present.
The reference to Amdahl’s Law is excellent...no calculation can be parallelized 100%, and there is always some upper limit on the gains to be had with parallelization. But there’s more to it than that. When we launch a new thread containing a parcel of rays to be traced, we also have to make a copy of the entire lens system for those rays to interact with. Making a copy of the lens data adds overhead, as does receiving the finished thread back and copying its data out, asking the operating system if it has room for more threads, and so on.
In non-sequential ray tracing it can be very difficult to estimate how many rays to trace per thread because the number of rays is not conserved. If ray-splitting or scattering is present, we may generate many more rays than the initial launch amount. So, while OS does use some good intelligent strategies to optimize the thread number, there is still room for the user to have some control as well.
BTW, in the context of specifying the number of cores when buying a new machine, more is always better (you can choose to use less if desired) but the amount of memory per core, and the type of memory per core is also very important. Each thread gets a full copy of the lens data, which may include CAD objects, Boolean objects, fluorescence and other scattering data and so on. That’s a lot of memory to move around (look at System...Check to see how much memory is needed per thread). It’s important that each thread can have that amount of cache memory per core so it doesn’t have to read and write to disk (even SSD) for this.
For sequential raytracing, I usually enter 18 cores (nearly the total number of threads available), but I’m not sure that setting is still optimal. Does Zemax still have a routine that I can use to compare optimization times with different settings? It looks like System Diagnostic is more of a graphics rendering test.
In sequential mode, the actual number of cores is probably the right value. Sequential files use much less memory, especially if they are all spherical.
Local Optimization with the damped-least squares optimizer is a special case. If you have n variables, you need (n+1) evaluations of the merit function to populate the Jacobian matrix, and OS will not use more than (n+1) threads as a result. So, when using local optimization, you may see fewer threads than the actual number of cores available, and this is the optimum for that calculation.
Tolerancing is also a special case. In sensitivity mode, if you have n processors OS will evaluate n tolerance operands simultaneously. In Monte Carlo mode it will evaluate n MC files at once, each on a single core. This is also the optimum value, unless you have something unusual about your system.
There’s no single benchmark for when to use however-many cores, as the optimum strategy is system dependent.
I was looking through your original post some more and I noticed that your machine has 32 cores but OS is defaulting to 64. My guess is that your machine is using hyperthreading, which is a scavenging technology used to make spare CPU cycles look like real cores. I’d turn that off. Try setting OS to just 32 cores and see what difference that makes. There’s usually a setting in the BIOS to turn hyperthreading off.
One of the developers did a research on these results to understand the reason of the time penalty when using too many cores.
The reason is given in @Mark.Nicholson’s answer. The ray trace code makes a copy of the system for every ray tracing thread. As the number of cores is increased, this leads to an increase in CPU time spent in memory access functions rather than in ray trace calculation functions. The severity of this effect varies between OpticStudio files and number of source analysis rays.
This effect is more pronounced the more complicated the system is, and the fewer analysis rays in the source. With few analysis rays, or complicated systems, the time spent tracing becomes less significant compared to the memory access associated with the multiple system copies.
currently I don’t have access to workstation PC, so I’ll have to wait some time till I try your suggestions. I don’t think it is Windows Power Management issue, but I will check again to be sure. I know I ended up using the tables provided by Sandrine and Ross to select for the optimal cores/ray values.
Dear All, I am coming back to this because the latest version of Zemax (22.0) no longer has this problem. I did not see this important improvement in the product announcement. Well done the Zemax team!
I checked with the developers and they confirmed not doing any changes (intentionally at least) that would optimize the number of threads/cores in NSC ray tracing.
It could be that your observation is a side-effect of some other change we made? Or have you done any change to the hardware or operating system that could have an effect?
I have played with the processors settings in the BIOS of my Workstation, toggled hyperthreading on/off, resetted BIOS to default configuration and then toggled hyperthreading on/off again. But I did not notice a difference in raytracing speed. Processor Power Management in Windows did effect the raytracing speed, but my setting was at 100% anyway. I don’t remember version of Zemax I used for the tests above but it is not the latest one, currently I don’t have time to do the tests with the latest Zemax version.