Hi Hans-Jürgen,
Unfortunately, I know they are slow :(
You can always send a feedback email to Zemax support and they might create a feature request for you. Its probably not going to happen in the short term though.
Opening and parsing an analysis window isn’t that bad. Its much easier and faster if the analysis is fully implemented, but the Zernike ones aren’t.
Here is an example for you:
# Open a Zernike Standard analysis
ZernikeStd = TheSystem.Analyses.New_ZernikeStandardCoefficients()
# Get analysis settings
Settings = ZernikeStd.GetSettings()
# Settings values
Field = 1
Surface = 3
Wave = 1
Samp = ZOSAPI.Analysis.SampleSizes.S_64x64
Vertex = False
Sub_x = 0.0
Sub_y = 0.0
Sub_z = 0.0
Eps = 0.0
MaxTerms = 25
# Update settings
Settings.Field.SetFieldNumber(Field)
Settings.Surface.SetSurfaceNumber(Surface)
Settings.Wavelength.SetWavelengthNumber(Wave)
Settings.SampleSize = Samp
Settings.ReferenceOBDToVertex = Vertex
Settings.Sx = Sub_x
Settings.Sy = Sub_y
Settings.Sz = Sub_z
Settings.Epsilon = Eps
Settings.MaximumNumberOfTerms = MaxTerms
# Apply settings and run analysis
ZernikeStd.ApplyAndWaitForCompletion()
# Save results to text file
Path = 'E:\ZernikeStd.txt'
ZernikeStd.GetResults().GetTextFile(Path)
# Close the analysis
ZernikeStd.Close()
# Read the text file
with open(Path) as F:
Lines = F.readlines()
# The relevant content seem to start at line 39 in the text file
# (hopefully this is conserved while modifying the settings)
# Read the relevant lines
for Index in range(38, len(Lines)):
# Split the line to isolate the numbers
SplitLine = Lines[Index].split()
# Term number
Term = int(SplitLine[1])
Value = float(SplitLine[2])
# Print the results
print('Z {0} \t {1: .8f}'.format(Term, Value))
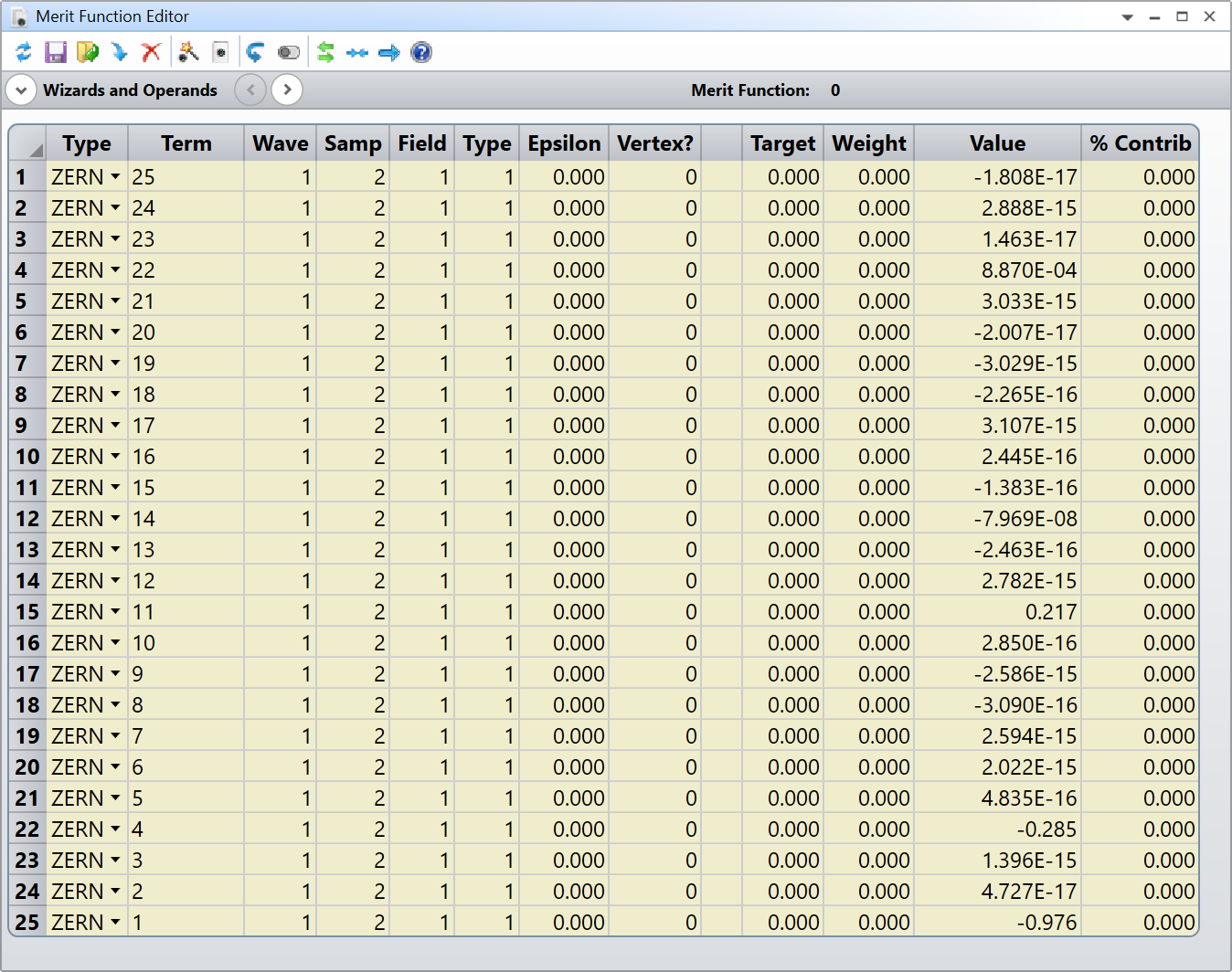
And the results for the same dummy file I did earlier:
Z 1 -0.97593483
Z 2 0.00000000
Z 3 0.00000000
Z 4 -0.28473181
Z 5 0.00000000
Z 6 0.00000000
Z 7 0.00000000
Z 8 0.00000000
Z 9 0.00000000
Z 10 0.00000000
Z 11 0.21694194
Z 12 0.00000000
Z 13 0.00000000
Z 14 -0.00000008
Z 15 0.00000000
Z 16 0.00000000
Z 17 0.00000000
Z 18 0.00000000
Z 19 0.00000000
Z 20 0.00000000
Z 21 0.00000000
Z 22 0.00088701
Z 23 0.00000000
Z 24 0.00000000
Z 25 0.00000000
Hope that helps.
Take care,
David