


Hi everyone,
I have written a code snippet to display a glass map of the materials that are found in the current lens file. I don’t think this is possible to obtain from the Libraries..Materials Analyses..Glass Map, but correct me if I’m wrong.
The full code is available on my GitHub.
These are the imports that are necessary in addition to what is already in the interactive extension or standalone template:
import matplotlib.pyplot as plt
from matplotlib.ticker import FormatStrFormatter
import numpy as np
import chardetThis is the actual code snippet:
# Glass catalog folder
cat_folder = TheApplication.GlassDir
# Number of surfaces
n_sur = TheSystem.LDE.NumberOfSurfaces
# List of materials
mats = []
# List of indices of refraction
refr = []
# List of Abbe numbers
abbe = []
# List of relative costs
cost = []
# Relative cost scale factor
scal = 100
# Material found flag
mat_found = False
# Loop over the surfaces
for ii in range(n_sur):
# Current surface data
sur = TheSystem.LDE.GetSurfaceAt(ii)
# Surface material
mat = sur.Material
# If the material isn't already in the list and isn't empty and isn't
# a MIRROR
if mat not in mats and mat!= '' and mat.casefold() != 'mirror':
# Append material to the list
mats.append(mat)
# Surface material catalog
cat = sur.MaterialCatalog
# Create a path to the catalog file
cat_path = os.path.join(cat_folder, cat)
# Check if catalog file exists
if os.path.exists(cat_path):
# Attempting to determine character encoding in the text file
# using chardet. This was taken from:
# https://stackoverflow.com/questions/3323770/character-detection-in-a-text-file-in-python-using-the-universal-encoding-detect
rawdata = open(cat_path, 'rb').read()
result = chardet.detect(rawdata)
charenc = result['encoding']
# Try to parse the catalog file for the specified material
with open(cat_path, 'r', encoding=charenc) as glass_cat:
for line in glass_cat:
# Try to find the material line
if line.startswith('NM ' + mat):
mat_found = True
mat_line = line
continue
# Try to find the other data line (for relative cost)
if mat_found:
if line.startswith('OD '):
od_line = line
break
# If the material data was found
if mat_found:
# Reset material found flag
mat_found = False
# Split material name line
mat_line = mat_line.split()
# Split other data line
od_line = od_line.split()
# Index of refraction
refr.append(float(mat_line[4]))
# Abbe number
abbe.append(float(mat_line[5]))
# Relative cost times scale factor
cost.append(scal * float(od_line[1]))
if cost[-1] <= 0:
cost[-1] = scal
# Plot results
plt.figure()
plt.scatter(abbe, refr, c=np.random.rand(len(abbe),3), s=cost, alpha=.7)
plt.grid()
plt.title('Current lens glass map')
plt.xlabel('Abbe number')
plt.ylabel('Index of refraction')
ax = plt.gca()
ax.yaxis.set_major_formatter(FormatStrFormatter('%.5f'))
ax.invert_xaxis()
for ii in range(len(abbe)):
ax.annotate(mats[ii], (abbe[ii], refr[ii]))
plt.show()This is the result for the Afocal Riflescope sample file:
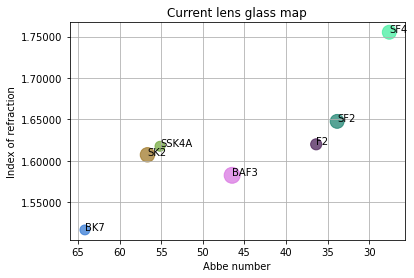
The size of the points is proportional to the relative cost (larger circles means greater relative cost), and if unknown, a relative cost of 1 is applied.
One important thing to note:
- The encoding of the different glass catalog files (*.AGF) seem to vary, the Schott one seem to be UTF-8, but the Optimax one is UTF-16. It makes it quite difficult to parse and there might be issues with the catalogs I haven’t tried yet. If we could know the binary format (*.BGF), it might make it easier to parse.
- EDIT: some glasses (like P-SF69 from Schott) have a relative cost of zero, I’m assuming that in this case, the relative cost is unknown although the value should be minus one.
Let me know if you find this useful and if it works for you.
Take care,
David