

Hello,
So I’ve been trying to optimise the processing speed for a macro where I test a large number of configurations. I initially did the usual-maximising # of cores, reduced analysis rays to minimum viable (about 1000, which is enough for total power)), but the process was still very long.
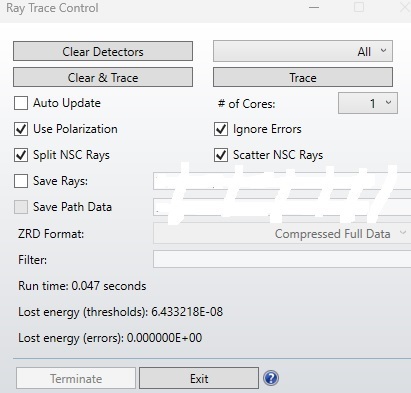
So then I re-checked the raytrace and somehow...fewer cores was faster? By a good order of magnitude. I am intensely confused by this result.
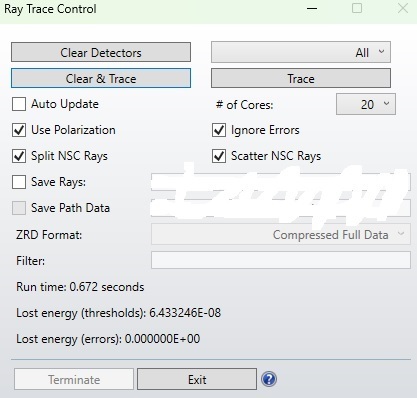
From googling a little, it might be an issue that shifting data between cores is more time-consuming than the individual processes. And with a larger amount of rays (10^6), multicore seems to be substantially faster. The result I’ve observed is confusing however.