Link: Max Cores
At the risk of repeating the question above, now I’m being more specific:
- How do I diagnose the reason that fewer than 100% of the cores are being used?
The model is:
- Sequential lens
- Merit function is the default minimum spot size with constraints on thickness / radii
- There are (x3) configurations for thermal
I am seeking Global Optimization solutions.
I have a “new” computer:
- (x32) Cores
- 128 GB RAM
When I started the optimization last night, the fan started spinning so I knew (?) it was working hard. This morning, all is quiet. (x7) of (x32) Cores are working on the problem and I have very little physical RAM in use as reported by the Windows Resource Monitor.
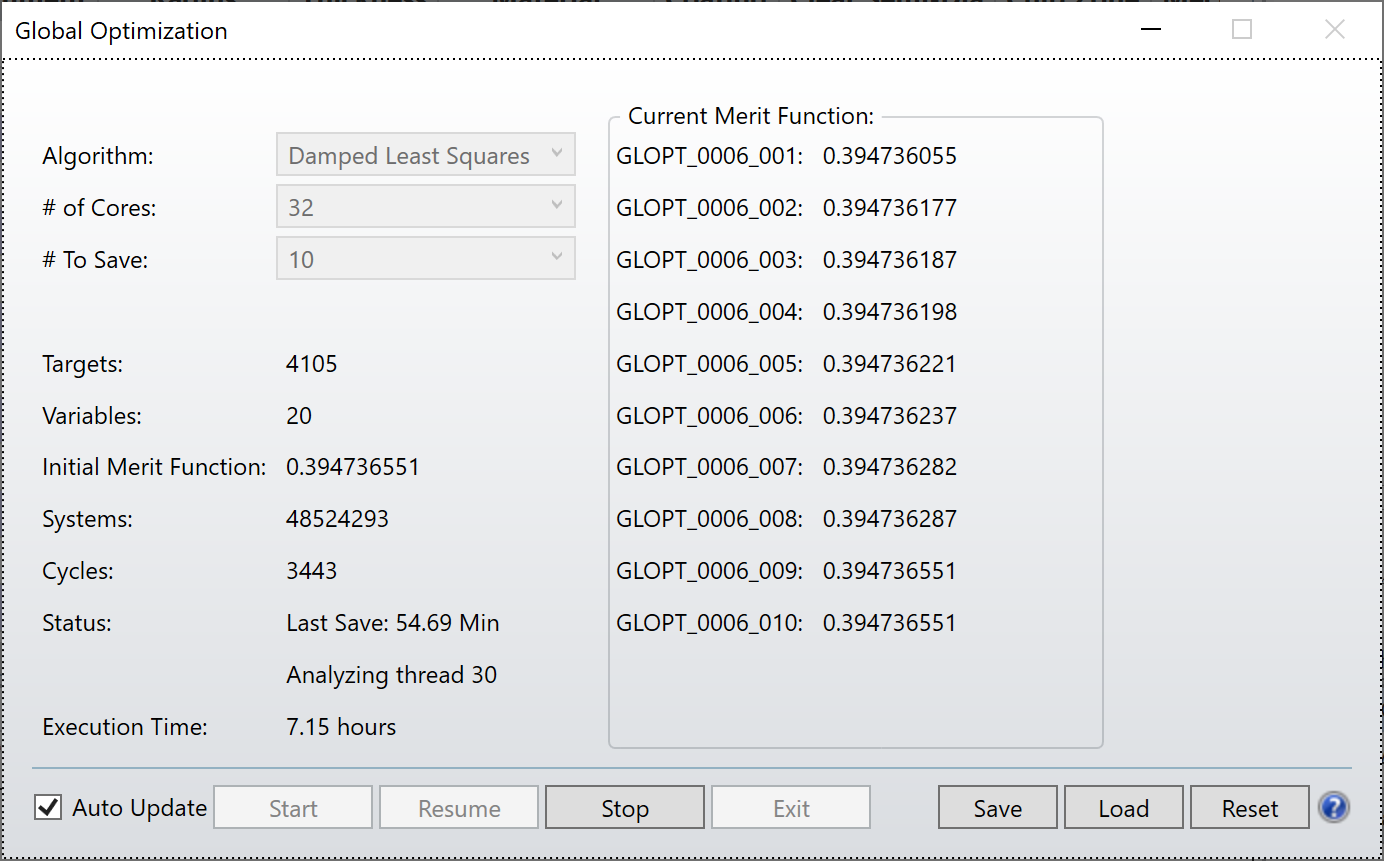
Referencing the question above:
- The number of assigned variables during the optimization (x20 variables and fewer than x20 cores used)
- OpticStudio will only use as many cores as the number of variables assigned
- The amount of RAM in your system (Way more memory available than cores)
- For each variable assigned, OpticStudio loads a copy of the entire system into memory before tracing/ evaluating.
- Systems with imported CAD parts can commonly run out of RAM before utilizing all available cores.
- To check the estimated memory required per copy of your system:
-

Way more memory that necessary
- For each variable assigned, OpticStudio loads a copy of the entire system into memory before tracing/ evaluating.
- Last, some Analyses/ Merit Function Operands can only be executed single-threaded (All Analyses windows are closed except the Spot Diagram and Layout. Which ones are single-threaded?)
- This could result in intermittent reduction in core usage during an optimization cycle.
- Closing Analysis windows did not increase the number of cores used
- Turning off Auto Update, increases the number of cores used for Hammer Optimization
- Turning off Auto Update for Global Optimization still doesn’t increase the number of cores to (x20 = number of variables)
- Just started another Global Optimization. (x19) variables. Right at the start, all (x32) cores are being used
- Does this imply that the number of cores is related to the progress in searching? or the remaining size of the optimization space that has been explored?