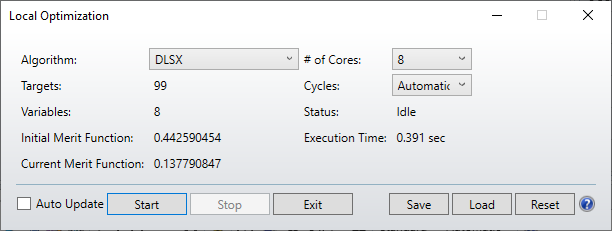
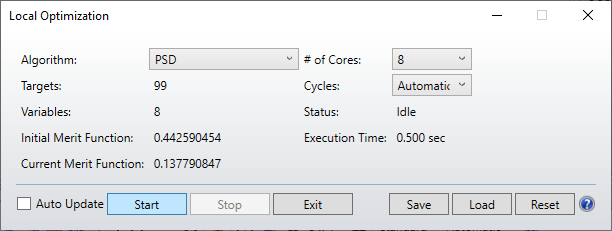
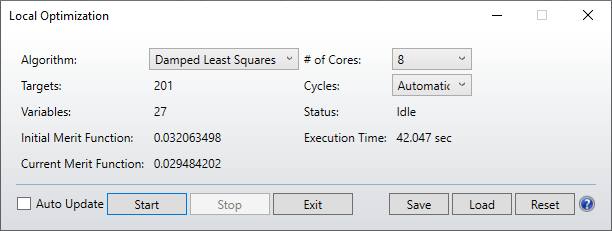
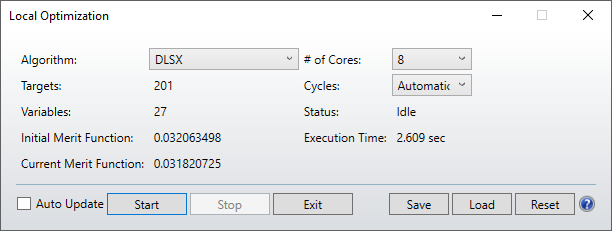
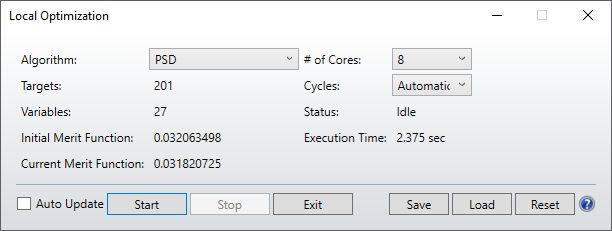
I was pleased to see the new optimization routines in 21.1, but I have not yet succeeded in getting a better result (either in MF value or speed) with them than with the DLS optimizer.
For example, in a typical imaging system design, optimizing for best RMS spot, I have a design with a starting MF of 0.02 with 12 variables, all thicknesses and radii. The results I get are:
DLS: 0.0011 in 1.7 secs
DLSx 0.0035 in 3.6 secs
PSD 0.0035 in 3.6 secs
For reference, Orthogonal Descent (which I know is not intended for this kind of optimization) gave 0.0037 in 2.9 secs. Can you give us some color on what kind of optimization problems these new algorithms are intended for?
- Mark
Best answer by Thomas Magnac
Hi Mark,
Happy new year! I hope you are doing well!
As you know, those new algorithms are in ''feature experiment'' which means that there is still work being done on it. (including documentation and use cases).
So far, this is my understanding from discussing with our developers:
DLSX – Streamlined DLS:
PSD – Pseudo-Second Derivative:
This is similar to our existing Damped Least Squares method but streamlined in some respects. For example, this method will not restart in “Automatic” cycle mode whereas Damped Least Squares sometimes will. DLSX also uses a somewhat different damping schedule and a more aggressive line-stepping algorithm. This method could be useful when the merit function is smooth, and the user wants a result as quickly as possible without worrying about some of the refinements that the Damped Least Squares method provides.
This is a modification of DLSX that uses a pseudo-second derivative when close to a local minimum to accelerate the ramping down of the damping factor during the optimization. The idea to use the pseudo second derivative is derived from Don Dilworth’s papers, but the implementation here which relies on DLSX for the bulk of the optimization trajectory is unique to OpticStudio. The effect of incorporating pseudo-second derivatives can be faster convergence near the optimum, at least in principle.
Hope it will help,
I'd be curious and interested to learn about more findings and feedback from users as to when those algorithms are most useful.
I'll be sharing my findings in this forum thread should I find anything of interest :)
As you know, those new algorithms are in ''feature experiment'' which means that there is still work being done on it. (including documentation and use cases).
So far, this is my understanding from discussing with our developers:
DLSX – Streamlined DLS:
PSD – Pseudo-Second Derivative:
This is similar to our existing Damped Least Squares method but streamlined in some respects. For example, this method will not restart in “Automatic” cycle mode whereas Damped Least Squares sometimes will. DLSX also uses a somewhat different damping schedule and a more aggressive line-stepping algorithm. This method could be useful when the merit function is smooth, and the user wants a result as quickly as possible without worrying about some of the refinements that the Damped Least Squares method provides.
This is a modification of DLSX that uses a pseudo-second derivative when close to a local minimum to accelerate the ramping down of the damping factor during the optimization. The idea to use the pseudo second derivative is derived from Don Dilworth’s papers, but the implementation here which relies on DLSX for the bulk of the optimization trajectory is unique to OpticStudio. The effect of incorporating pseudo-second derivatives can be faster convergence near the optimum, at least in principle.
Hope it will help,
I'd be curious and interested to learn about more findings and feedback from users as to when those algorithms are most useful.
I'll be sharing my findings in this forum thread should I find anything of interest :)
Thanks for that. I guess though I still don't see the benefit. I could get 'the user wants a result as quickly as possible without worrying about some of the refinements that the Damped Least Squares method provides' if that meant getting a less well-optimized result in less time (though you don't have to use the Automatic button in that case, just run a finite number of cycles). But my testing shows a less-well optimized design in longer times. And I reproduced that with a fixed number of cycles: using just 5 cycles, the DLS optimizer got a lower (better) result faster. I also found this with multiple designs I tried.
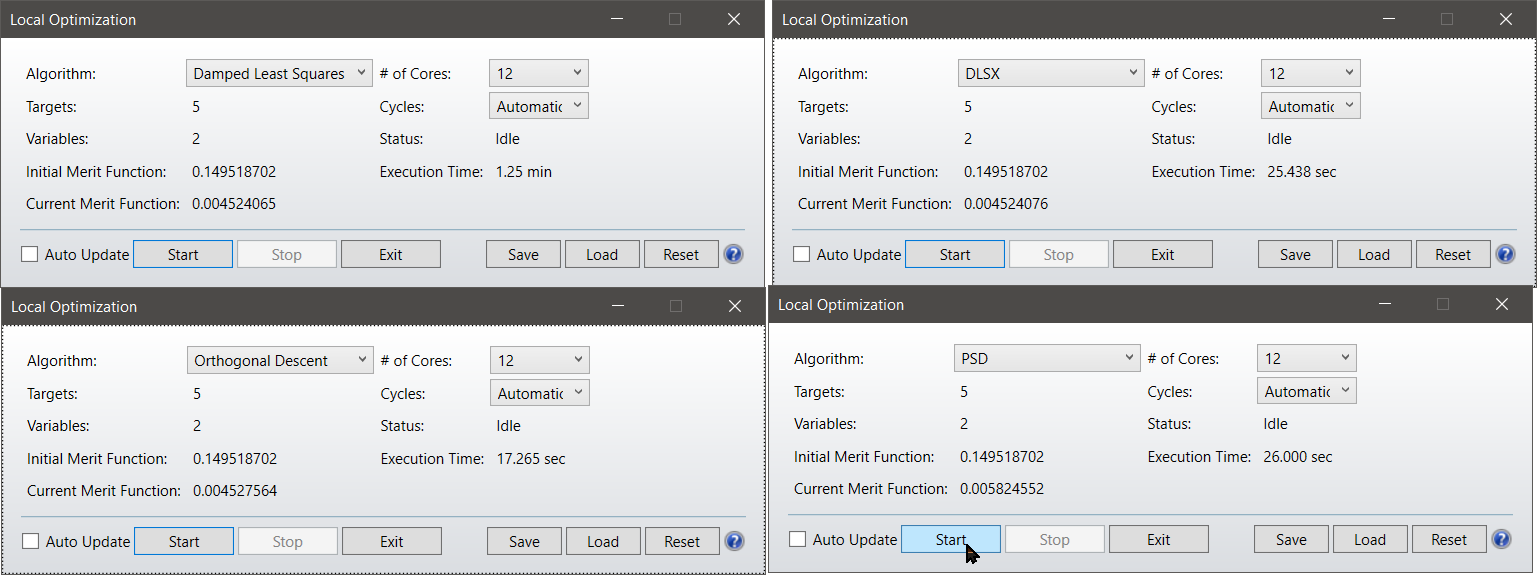
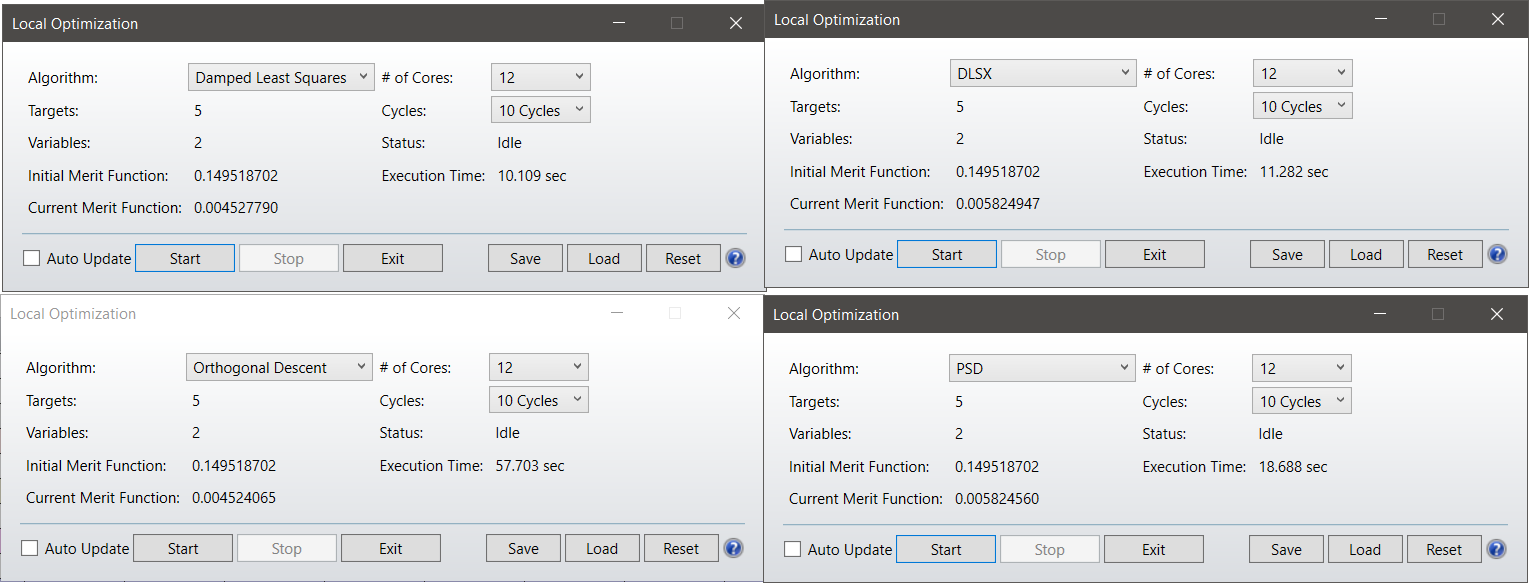
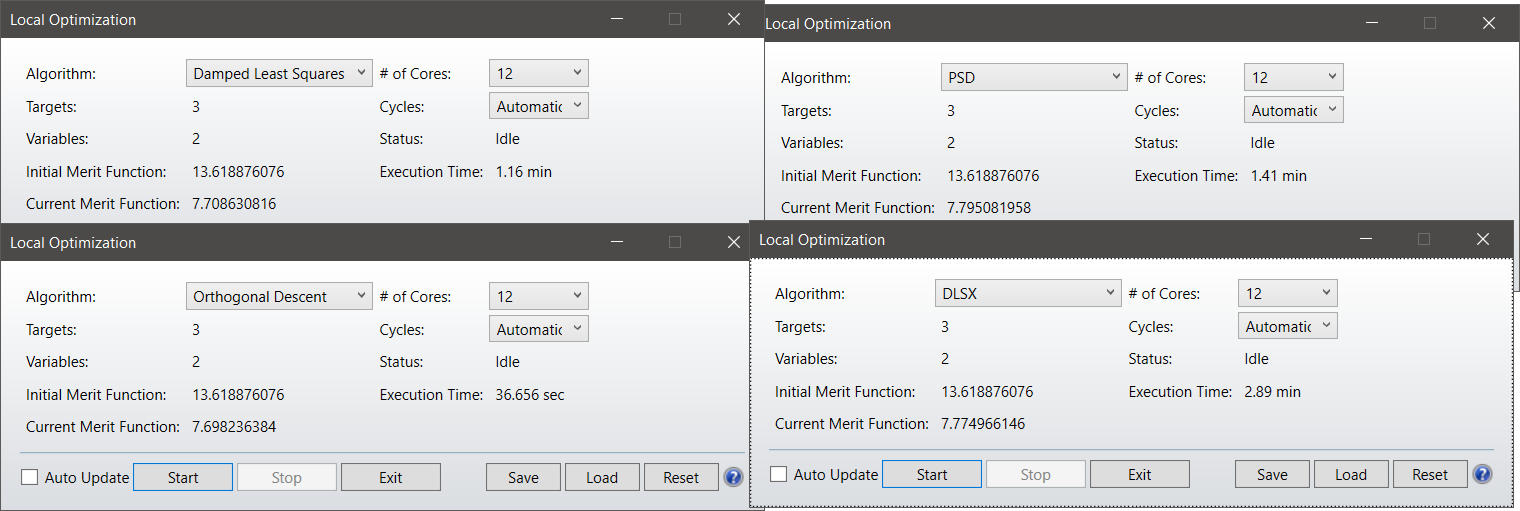
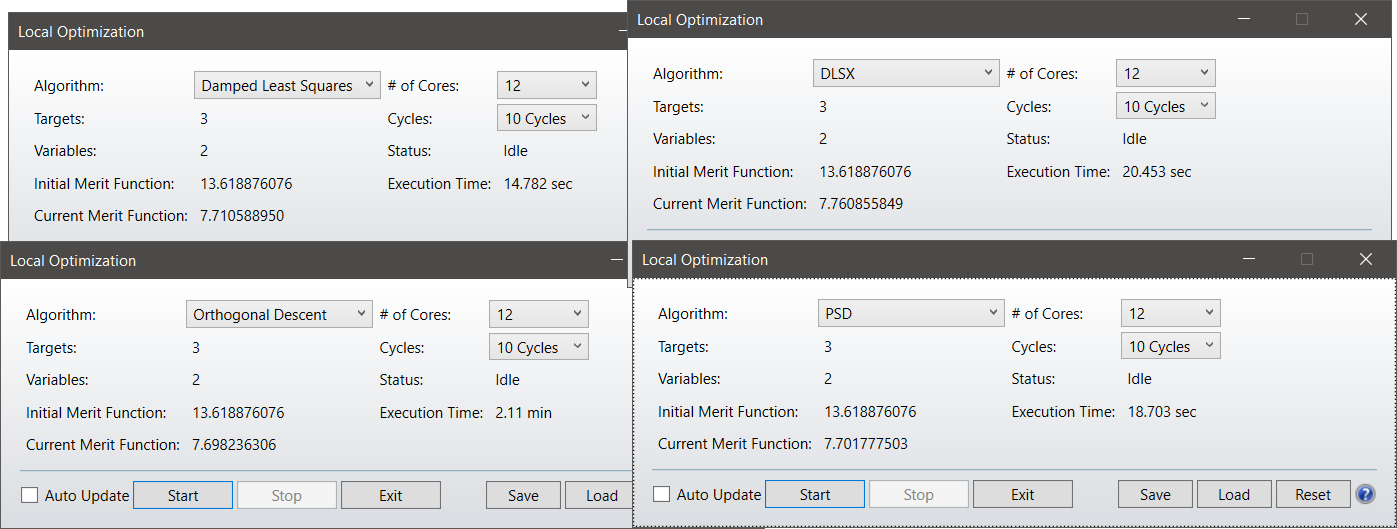
I would like to share some results that I got when optimizing a simple reflector in non-sequential. I have taken screenshots at the end of the optimization, the starting point for all 8 cases is the same.
-This is for ''automatic'' number of cycles:
-This is for 10 cycles:
We see, that with a simple non-sequential system, with a small number of variables which are decoupled, OD is the best, followed by the new DSLX.
>I want to highlight the fact that PSD is simply failing at finding the same results as the other algorithms.
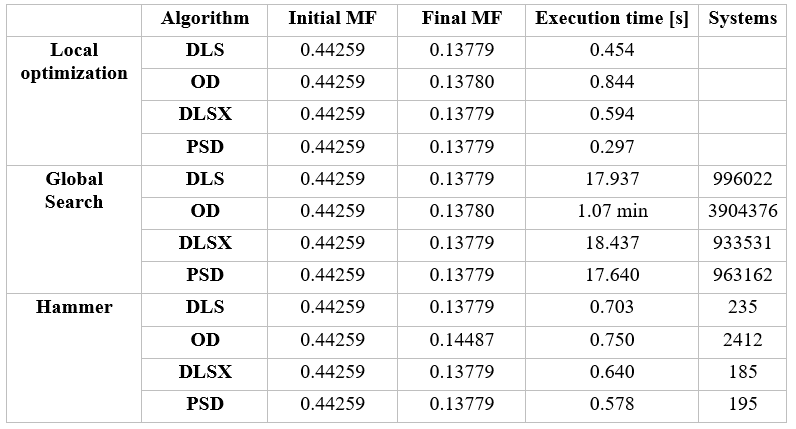
I used the attached Cooke 40 degree field_start.zar file as the starting point for my optimization runs. In case of Local Optimization, I ran 50 cycles and recorded the execution time and the resulting merit function value. For Global Search, I targeted to run 1000 cycles, and recorded the number of tested systems besides the final merit function value and the execution time. For Hammer, I used the Automatic mode.
You can find my results below:
We can see that in this test case OD performs worse than the other 3 algorithms. The other 3 methods coverge to the same result within similar times, PSD is a bit faster than DLS and DLSX.
Thanks for that. I have a couple of thoughts on this, but it all comes down to the issue of 'when do you know to use what method?'.
We've known for a long time that if you just fiddle with adjustable parameters in the code (not available to the end user) that you can improve the optimizer for any specific file. The problem is that it worsens all the others! The existing values of those parameters was a compromise of results over a batch of test cases.
The problem I have with the new optimization methods as implemented is that there is no way to know in advance which one works best, at least from the perspective of an end user who is not running the raw code in Run mode inside Visual Studio. In contrast, the improvements made in the previous release, 20.3, to the optimizer improved optimization for all systems across the board, no questions asked :-)
I'd like to suggest a couple of things for testing:
1. Only compare Local optimizers against each other. Hammer and Global both use extensive randomization methods, and no two runs of these give exactly the same results or take the same amouint of time. Try repeating any of the Hammer or Global tests three times, with the same local optimizer and starting conditions. You'll get three different results, and you'll have no way of predicting in advance which run will be best :-)
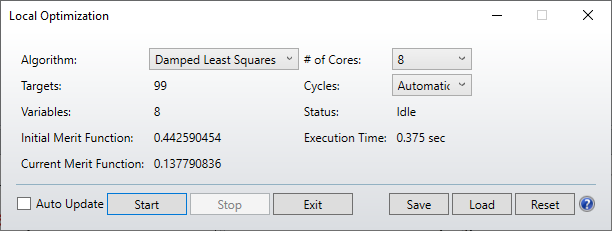
2. Have a minimum complexity test case. I think Tom's two-variable, 5 target optimization is too simple. You can do a two variable system by hand: the optimization algorithms should be judged by systems that are not capable of being solved in closed form. Csilla's 8 variable, 99 target system should be the minimum complexity in my (not very) humble opinion. Try a multi-config systems with 20 variables/config and see what happens!
3. Always use Automatic mode. Just running a fixed number of cycles is a data point, to be sure, but the goal should be to keep it simple for the user. With Csilla's Cooke, I used Automatic mode, and again DLS always gave a better value more quickly:
4. Test the new methods for tolerancing, in case they have benefits for that special case (see below)
BTW, OD should not be used for things like imaging system design except in tolerancing. OD is intended for systems where the MF is discontinuous, as is often the case in non-sequential mode. This KB article sets out the differences. We also found an important secondary use for OD: in systems that have a very shallow 'capture basin', a slowly-varying merit function around a minimum, OD zeroes in on the minimum faster than the gradient search DLS. That's why we use it in tolerancing, where the systems are perturbed from a good system and the job is to recover performance.
Sorry to bang on, but the topic of optimizing optical systems is dear to my heart :-)
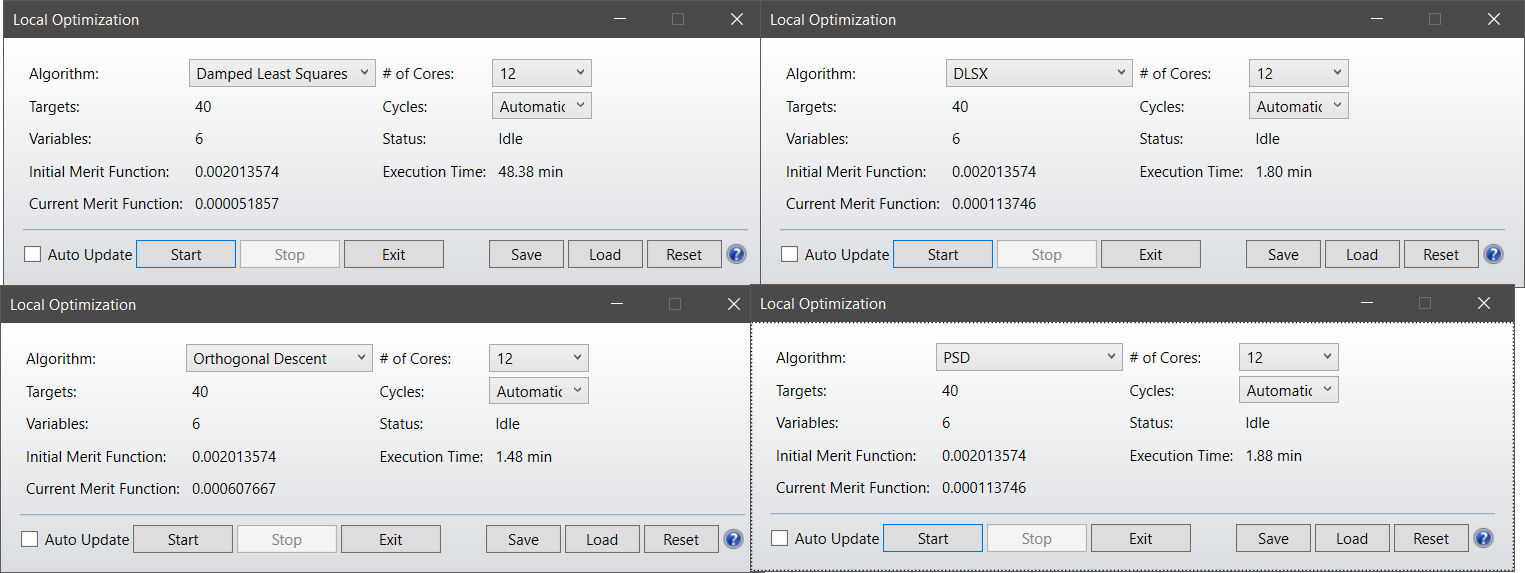
I opened up the sample file Samples\Short course\Archive\sc_zoom3.zmx, which is a zoom lens, three configs, all set up with a merit function and ready to optimize. Here's what I got:
So only the DLS makes any progress with this 27-variable system. The other two run long enough to see that they're not going to make progress and quit.
I think your question 'when do you know to use what method?' is likely shared by quite a few OpticStudio users out there, so I want to address that question directly. You're right that Zemax hasn't provided any guidance to our users about when the PSD or DLSX algorithms should be used in place of DLS or OD. That guidance is exactly what we're working to define. In contrast, we teach within our training course material that OD is beneficial for non-sequential optimization due to the non-linearities that you mentioned while DLS is good for smoothly varying MFs/variables.
So why did we develop PSD and DLSX? Zemax is always looking to expand and improve the toolkit that we make available to our users. In particular, we know that optimization speed and quality of results are some of the most important factors that we can influence, so we are testing these algorithms to identify scenarios, themes, rules of the road where they prove useful. While we're conducting our own tests (which go beyond this forum thread), we're also excited and interested to hear feedback from our users who wish to test out the algorithms on their own systems.
Can you share some of the files from your more extensive testing where you get improved performance from the new algorithms? I'm sure there is some scope for them to be useful, but I just haven't found it yet. C'mon, throw me a bone :-)
I chatted some more with Shawn and Brian (R&D) on this topic, and they made a few points that I found quite illuminating:
The original DLS algorithm is still best in many cases (this is good, as it means that the go-to algorithm stands the test of time) but the new algorithms may offer an advantage in the places where DLS would previously get stuck. This is where we're both doing internal testing and particularly looking for user feedback, but we haven't seen anything notable yet.
Even for local optimization runs, the speed of optimization can vary considerably from one run to another due to background activity on one's computer. In order to assess the relative speed of differnt algorithms, one must account for this and then collect statistically meaningful data.
While PSD algorithm is still a local optimizer like DLS, it takes a different path to a solution. So, if the solution space has multiple local minimums, the PSD algorithm may find a different solution than DLS.
In general, it is impossible to know what local optimizer will work best for a given situation. There are guidelines, such as Orthogonal Descent is more suited to non-smooth objective functions than DLS, but even with that in any one case DLS could get lucky and happen to converge faster. And DLS, DLSX, and PSD are all targeted to relatively smooth objective functions.
I searched the manual for any mention of DLSX (streamlined DLS) and PSD (pseudo-second derivative) optimization methods, and found nothing. Then I found this thread, so I am glad to learn from Thomas's post what on earth these two algorithms are supposed to be in the first place. Just mentioning that they exist and that they are experimental, and leaving it at that, is not really helpful. I did not realize that experimental features have no documentation whatsoever. That they are there for the user to discover and comment on is actually understandable, but I did not know that that is the policy. It would be helpful to spell this out explicitly for all users, but to also give us a bit more than breadcrumbs in the release notes.
That said, here are my thoughts on optimization. I am excited to learn that Zemax is putting effort into its optimization algorithms. For complex lens design applications, this is probably the most useful thing Zemax could be working on. All the examples discussed in this thread so far have very few variables and do not stress-test any algorithm very much, including the most complex example Mark tried of sc_zoom3 with 27 variables and 207 operands in the MF. Each optimization cycle takes a fraction of a second. What about real-world designs, sometimes with 10-20 configurations, hundreds of variables, and 120,000 operands? There a single optimization cycle can take 3-5 minutes, and it becomes frustrating to see after that time waiting that the optimizer does not budge. Contrast that with CODE V, where the exact same design, with the same constraints, computes an AUT cycle in 1 second or less, and the design actually starts to move. There really is no comparison. Part of the problem is with multi-configurations in the first place. If I dezoom a complex let’s say 10 config system down to a single config in Zemax, keeping the same operands for that config and tossing the rest (so that would bring the MF down to say 12,000 operands, so still a fairly sizeable number), then the computation time in Zemax also might go down to a few seconds per optimization cycle. The difference between Zemax and CODE V, however, is that CODE V does not slow down by orders of magnitude when adding many configs. It barely notices. I don’t know if that is a function of the optimization algorithm, or the overhead of handling multiple configs, or both, but doing highly complex things in Zemax can be fairly unproductive.
Putting my frustration with Zemax speed aside, here are some further thoughts on optimization. Again I am talking about complex systems with many variables and operands. There are times when the optimizer is near a minimum, but continues to move almost forever, but in very small increments. This happens in any lens design code, not only Zemax. You can let the DLS run for hours, and still it continues. If you keep it on infinite cycles and let it run overnight, you may have a very different and often better system than if you had stopped when the Automatic cycle algorithm would have decided to stop. (if you had done a regular Hammer overnight, it might have found that solution, or some other solution, or there are times when it stagnates as well). This is the scenario where the power of having different optimization algorithms at one’s disposal becomes very useful. These algorithms can help stagnated systems move, and you don’t have to wait overnight. I have a recipe for doing this in Zemax which is not documented, and I have never heard anyone else discuss it before: let’s say you let one of these systems run for hours on infinite DLS, and it truly has stopped moving. Now you go to the Hammer optimizer, and instead of selecting the “Start” button, you click on the “Automatic” button (still using the regular DLS algorithm). In many cases this will start moving the design, instantly. After a few minutes you go back to Local Optimization, using Infinite cycles, and the design continues to move (slightly faster than Automatic does in Hammer), even though it had completely stagnated just moments earlier after hours of infinite cycles. When it stagnates again, you go back to Hammer Automatic and continue the process. Incidentally, the Automatic in Hammer also might stop on its own (as it apparently does not do infinite cycles), so then you simply either hit Automatic again, or go back to Infinite Local optimization. In both cases it will continue to move. Often you can get a design to go significantly further this way. The Automatic feature in Hammer is also hardly documented, so I do not know what actually is going on, but it is neither the genetic search algorithm of the real Hammer, nor the regular DLS of the local optimizer. So there is an example of an “experimental” optimizer in Zemax that no one has bothered with figuring out. It would be good to have in the manual what the Automatic button in Hammer is actually intended to do.
It was also an eye-opener when Mark mentioned that the raw Zemax code has adjustable parameters that greatly influence the speed and outcome of optimization runs. Just for everyone’s understanding, CODE V makes some of those handles available to the user in their optimizer, and it can greatly influence the direction a design will take (not the speed, since it is so fast already). If the user does not want to bother with any of that, the default settings will do the job just fine most of the time.
Hey Georg, could you drop me an email at markgnicholson(at)gmail.com please? You've sparked a couple of thoughts I'd like to follow up with you directly.
This is a fascinating thread. I too agree with Georg. I often am up against a wall when optimizing above 20 or 22 variables and have developed techniques to work around this. Since I'm not formally trained, I've assumed for years there's a gap in my knowledge. Yet some of the workarounds I've developed are little hacky tricks like that mentioned by Georg. So I was personally happy to see the introduction of these two new optimization techniques. Unfortunately, neither PSD nor DLSX helped me in the problems that I face.
Like Georg, I've also noticed that there are 'hidden variables' that I can't access, but improve optimization. Often I'll locally optimize (LO) until the optimizer reaches a minimum, close the LO window, reopen it, and optimize again. Clearly there's some damping parameter or something, but I can't adjust it and so I have to play these games. I'd love to access these variables. They may not even do much, but sometimes having something to play with may help increase the creative magic.
Georg hit the nail on the head. CODEV optimization really is much better than Zemax. It simply finds better solutions, much faster. For years, I didn’t believe this, I thought it was just propaganda. Then I had to learn CODE V for a new job, and I saw that it was absolutely true.
In addition, a very experienced colleague who uses both CODE V and Synopsys (Don Dilworth’s code) tells me that Synopsys “finds solutions that CODE V never would”. A second colleague, also very experienced, says “Synopsys blows the doors off CODE V, and Zemax is a distant third”.
Synopsys can also automatically add and delete elements as-needed to achieve the necessary performance (you tell it the max number of elements it’s allowed to use).
So it appears that there is indeed value in Dilworth's PSD algorithm.
I really hope Zemax continues improving the optimization. It’s really the only reason I ever use other codes.