Hi Zemax Community,
I am doing a design with my operand to optimize the optical system.
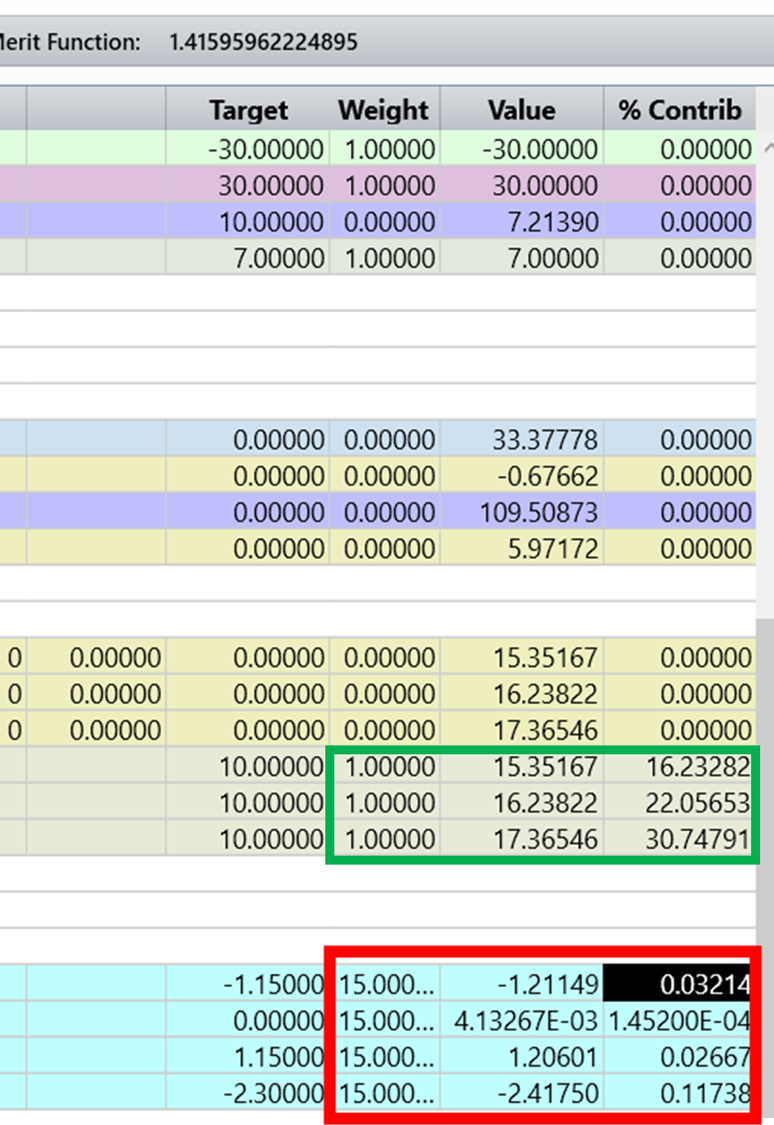
As part of operands are set as below.
For example, I set 15 to the weight of the most important operands here in red box. and others are 1 in green box.
My question is
- when zemax does the optimization, whether it selectively focuses on optimizing the heavier weight firstly and then other lower weight operands?
- or Not the weight, but the contributions are considered? zemax would focus on the more contribution operands firstly?